5 Technical details
CyITP is developed in the R Programming language and is an open source project. The code is available at https://github.com/cyipt. CyIPT consists of two main parts; the R based analysis code, and the website, which is a mixture of HTML/CSS/JavaScript with a PostgreSQL database accessed via a PHP-based API.
This manual focusses on the R based analysis code, as the website exists purely for visualisation and ease of use.
5.1 Data Preparation
CyIPT is reliant on some pre-existing datasets from third parties. While many of these are publicly available, CyIPT required them to be pre-processed before use. These scripts are provided for context, but in most cases, users should download the pre-processed data directly from GitHub.
5.2 CyIPT Master Script
The CyIPT master script https://github.com/cyipt/cyipt/blob/master/scripts/cyipt.R can be used to run the whole CyIPT process. It manages several global settings.
5.3 Settings
Should the code skip regions that have already been done?
overwriteSome stages overwrite existing files, for example by adding an extra column of data. Note that not overwriting may cause later stages to fail if they expect earlier stages results to be in the starting file.
ncoresSome functions use parallel processing how many clusters should be run? This should be less than the number of cores on your computer.
verboseGet extra messages and information while CyIPT is running.
all.regionsIgnore the regions to do file and run for all regions.
5.4 Regions to Do
If all.regions = FALSE CyIPT will choose which regions to run for based on the RegionsToDo file at https://github.com/cyipt/cyipt/blob/master/input-data/RegionsToDo.csv
Placing y in the do column of this csv file will rerun the that region.
CyIPT uses the 2011 travel to work areas produces by the Office for National Statistics (ONS). Other boundaries could be used in the future.
5.5 Libraries
CyIPT requires the following R libraries, which can be installed as follows:
pkgs = c("sf",
"osmdata",
"stringr",
"dplyr",
"parallel",
"xgboost",
"igraph",
"tmap"
)install.packages(pkgs)and loaded as follows:
vapply(pkgs, require, TRUE, character.only = TRUE)## sf osmdata stringr dplyr parallel xgboost igraph tmap
## TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE5.6 Step 1: Download the Data
https://github.com/cyipt/cyipt/blob/master/scripts/prep_data/download-osm.R
This script downloads the OSM road and path network for each region.
Inputs:
Regions.todo
Boundaries file “../cyipt-bigdata/boundaries/TTWA/TTWA_England.Rds”
Outputs:
Region Boundaries “../cyipt-bigdata/osm-raw/region/bounds.Rds”
OSM road network “../cyipt-bigdata/osm-raw/region/osm-lines.Rds”
OSM road junction points “../cyipt-bigdata/osm-raw/region/osm-junction-points.Rds” Parallelised:
Yes
5.8 Step 3: Get traffic counts
https://github.com/cyipt/cyipt/blob/master/scripts/prep_data/get_traffic.R
This script assigns the point traffic count data to the road network.
Inputs:
Regions.todo
OSM road network “../cyipt-bigdata/osm-clean/region/osm-lines.Rds”
Traffic Points “../cyipt-bigdata/traffic/traffic.Rds”
Outputs:
OSM road network “../cyipt-bigdata/osm-clean/region/osm-lines.Rds”
Parallelised:
No
5.8.1 Details
This scrip divides the point traffic counts based on whether they are on classified (e.g. M21, B340) or unclassified roads. Unclassified road points are matched to the nearest road in the OSM, and therefore the value only extends a short distance from the point location. For classified roads, a series of Voronoi polygons are constructed around the points and all the road segments within each polygon are assigned the value of their nearest point. This provides continuous coverage, but can produce some erroneous results such as off ramps having the same traffic levels as the main carriageways.
In both cases, the script takes the Annual Average Daily Traffic (AADT) value from the most recent available year. For the strategic road network, data is mostly from 2015/2016, but for minor roads, it can be significantly earlier. For the purposes of CyIPT is the traffic data is mostly used for identify the very busy and most hostile roads, thus this inconstancy of data is not a significant problem. However, users intending to use the data or method for other purposes should consider the implications of this inconstancy within the data.
5.9 Step 4: Split the lines at each junction
https://github.com/cyipt/cyipt/blob/master/scripts/prep_data/prep_osm.R
This script splits the roads at each junction into road segments.
Inputs:
Regions.todo
OSM road network “../cyipt-bigdata/osm-clean/region/osm-lines.Rds”
OSM road junction points “../cyipt-bigdata/osm-raw/region/osm-junction-points.Rds”
Outputs:
OSM road network “../cyipt-bigdata/osm-prep/region/osm-lines.Rds”
Parallelised:
No
5.9.1 Details
The splitting of the roads at junctions is mostly required for the later application of the PCT data. Within the OSM a road may be represented by a single long line crossing several junctions. However, at each junction cyclists may join or leave the road. Therefore, it is not appropriate to analyse the road network as it is represented in the OSM. By splitting the road network into segments it ensures that, the analysis is appropriately detailed. Note the splitting is done by cutting tiny holes out of the road lines (r = 0.01m) therefore the lines are no longer touching; this would prevent this dataset being used in a routing engine.
5.10 Step 5: Get the PCT estimate of number of cyclists
https://github.com/cyipt/cyipt/blob/master/scripts/prep_data/get_pct.R
Inputs:
Regions.todo
OSM road network “../cyipt-bigdata/osm-prep/region/osm-lines.Rds”
PCT LSOA Routes “../cyipt-securedata/pct-routes-all.Rds”
TTWA boundaries “../cyipt-bigdata/boundaries/TTWA/TTWA_England.Rds”
Outputs:
OSM road network “../cyipt-bigdata/osm-prep/region/osm-lines.Rds”
PCT LSOA Routes (Regional) “../cyipt-securedata/pct-regions/region.Rds”
PCT to OSM lookup (Regional) “../cyipt-bigdata/osm-prep/region/pct2osm.Rds”
OSM to PCT lookup (regional) “../cyipt-bigdata/osm-prep/region/osm2pct.Rds”
Parallelised:
Yes
5.10.1 Details
This script matches the Propensity to Cycle Tool (PCT) LSOA route data with individual road segments to count the number of cyclists on each road segment. Values from each of the five PCT scenarios are recorded:
Census 2011
Government Target
Gender Equality
Go Dutch
EbikesWhile the matching process is reasonably robust, small errors can occur resulting in missing segments, or double counting.
As the PCT data was unidirectional routed (A to B, but not B to A) the results are less accurate on dual carriageways. For example, the PCT is constructed from Census 2011 Origin-Destination data matched to routes produced by CycleStreets. The Origin and Destinations are Lower Level Super Output Areas. The census state that 30 people live in LSOA A and work in LSOA B, and 50 people live in LSOA B and work in LSOA A. The CycleStreets provide a route from A to B, and the PCT assign this route a value of 80 (50 + 30). This method does not therefore take account of the route A to B being different from the route B to A, due to one way streets, roundabouts etc. Nor does it consider that commuters return home at the end of the day.
In these cases, the number of cyclists is split between the carriageways with usually with most on one carriageway (see Figure 5.1).
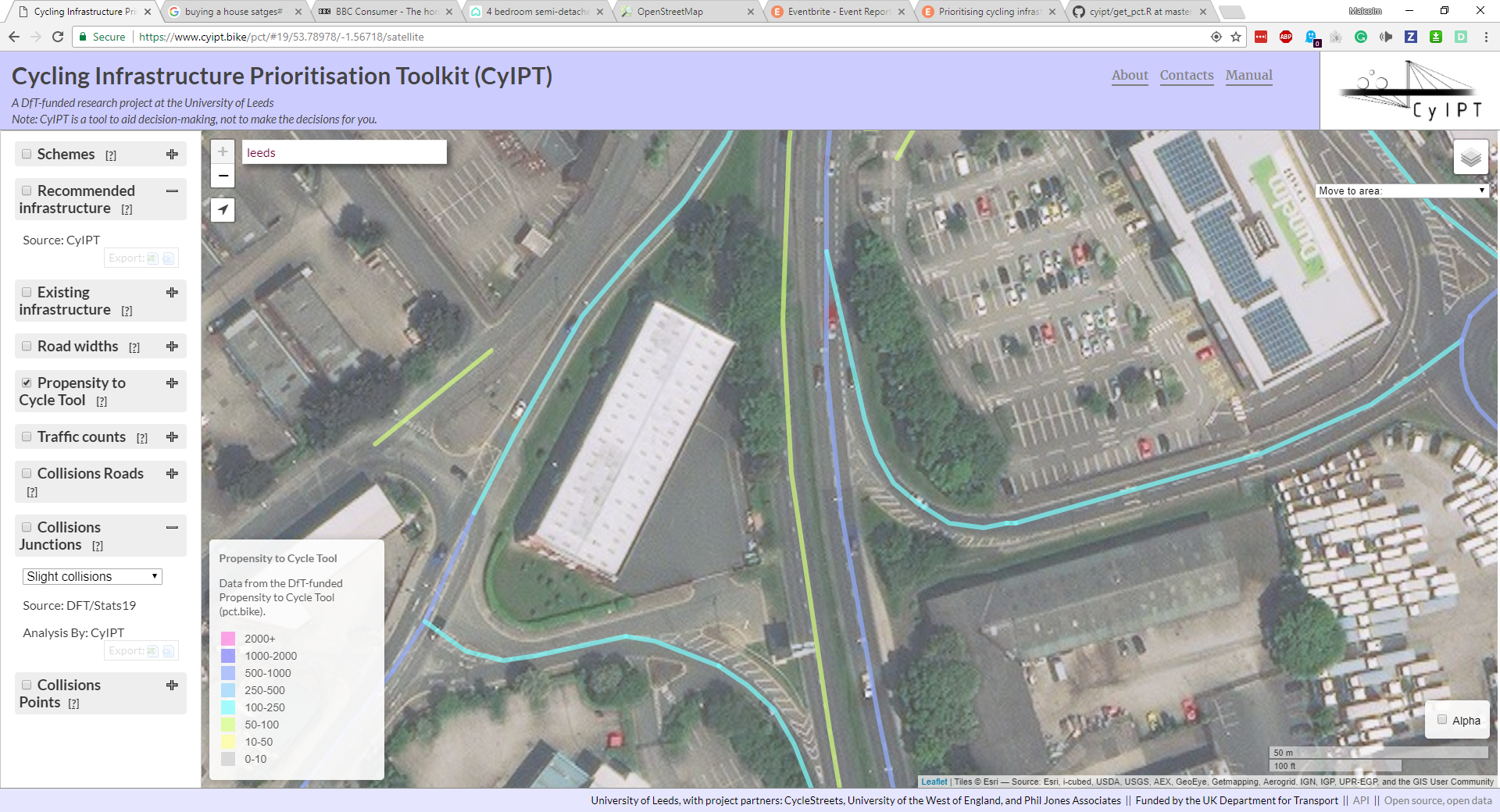
Figure 5.1: Effects of Unidirectional Routing.
5.11 Step 6: Get road width estimates and collisions
source("scripts/prep_data/get_widths.R")
source("scripts/prep_data/get_collisions.R")5.12 Step 7: Evaluate Infrastructure Options
source("scripts/select_infra/select_infra.R")5.13 Step 8: Compare Widths Needed to Widths Available
source("scripts/select_infra/compare_widths.R")5.14 Step 9: Group into schemes
source("scripts/select_infra/make_schemes2.R")5.15 Step 10: get uptake and benefits
source("scripts/uptake/calc_uptake_routechange3.R")